ANZINE : CAE 기술 매거진
이전 ANZINE Home Tech-Insight


Native GPU Solver가 제안하는 CFD 시뮬레이션 가속 기술과 비용 효율화
- 이광희 수석매니저
- 태성에스엔이
- kwang281@tsne.co.kr
Native GPU Solver가 제안하는 CFD 시뮬레이션 가속 기술과 비용 효율화
(Ansys Fluent® Native GPU Acceleration Technolgy)
n Introduction
지난 1년간 수십 차례의 벤치마크와 실제 문제를 다루면서, 한 가지 확신을 갖게 되었다. Ansys Fluent®의 Native GPU Solver는 CFD 엔지니어가 오랜 기간 마주해 온 어떠한 구조적 한계를 정면으로 돌파하는 실질적인 솔루션이라는 점이다. 이번 호에서는 Tae Sung Tech Summit 2026에서 발표한 내용을 바탕으로, 왜 지금 CFD 시뮬레이션도 GPU Solver를 진지하게 검토해야 하는지를 데이터와 사례로 이야기하려고 한다.
새벽 2시, CFD 엔지니어의 풍경

[그림 1] 자포자기한 CFD 엔지니어의 풍경
보고서 마감은 아침 8시, 시계는 새벽 2시 30분을 지난다. 오른쪽 모니터에는 1/3도 끝나지 않은 Fluent 진행률 표시가 깜빡인다. 격자를 한 번 더 조밀하게 만들면 주말이 사라지고, 계산이 한번 발산하면 며칠이 통째로 날아간다. 하지만 팀장님과 그룹장님은 이런 사정을 기다려주지 않는다. CFD 엔지니어라면 누구나 한번쯤 마주했을 풍경이다. 그렇기 때문에 어떻게든 계산을 빨리 끝내는 방향으로 현실과 타협을 하게 된다. 이런 타협의 일상은 개인의 역량 문제만은 아니다. CFD 계산이 오래 걸리는 진짜 이유는 방대한 계산량에 비해서 지난 20년간 ‘어떤 한계’ 때문이다. 그리고 그 한계를 이해하기 위해서는 CFD 엔지니어가 마주한 ‘세 가지 숙명적인 과제’를 정리해볼 필요가 있다. [그림2]

[그림 2] 오늘날 CFD 엔지니어들이 직면한 3대 핵심 과제
CFD 엔지니어는 Scale, Speed, Accuracy라는 세 가지 요소에 대해 항상 고민한다.
실제 산업 현장의 장비들은 규모가 크고 복잡하며, 수준 높은 Physics 모델을 필요로 한다. 그렇기 때문에 수천만에서 수억 개의 격자를 필요로 하지만 계산 시간이 증가한다는 문제가 발생한다. 시뮬레이션이 아무리 정확해도 보고서 마감일이나 제품 출시일 전에 끝나지 않으면 의미가 없다. 그렇기 때문에 CFD 엔지니어가 ‘현실과 타협’해 온 모든 결정은 사실 이 세 가지 요소의 어느 한 꼭짓점을 포기한 결과였다.
그런데 만약, 계산 속도가 10배, 100배 빨라진다면, 같은 기간에 100번의 Parametric Study를 실행해서 진짜 최적 설계를 찾을 수 있지 않을까? 계산 속도만 빨라져도 CFD 시뮬레이션의 차원이 달라진다.
n CPU의 한계, 그리고 GPU라는 우회로
그렇다면, 왜 이제서야 가능한 것일까? 그 답은 Karl Rupp 박사가 정리한 데이터(Karl Rupp’s microprocessor trend data)에서 쉽게 찾아볼 수 있다. CPU는 2004년 이후 사실상 연산 속도가 거의 증가하지 못했다. 하지만 멀티코어와 병렬화를 통해서 처리 속도를 향상시키는 전략을 이어왔고 Ansys Fluent도 이러한 흐름을 꾸준하게 따라왔다.
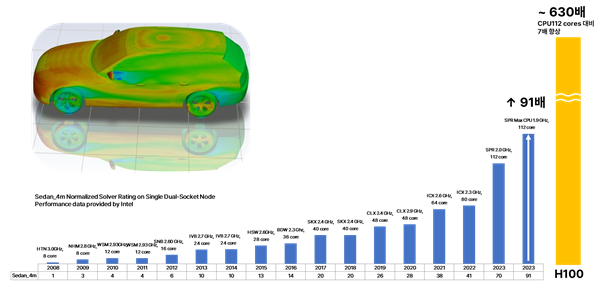
[그림 3] Ansys Fluent의 단일 노드 성능 히스토리 (CPU VS GPU)
[그림 3]은 이러한 흐름을 보여주는 하나의 지표를 나타낸 것이다. 그래프는 동일한 벤치마크 테스트를 2008년 8코어 대비 계산 속도 향상을 나타낸 그래프이다. 2023년 112코어에서 91배의 성능 향상을 달성했지만, 시뮬레이션 규모와 정확도에 대한 요구가 끊임없이 높아지는 현실에서 91배의 향상은 만족스러운 답이 되지 못하고 있다.
여기에 GPU가 등장한다. GPU는 본래 그래픽 연산을 위해 설계되었지만, 오늘날 결과적으로 CFD의 속도 향상에 완벽하게 부합하는 구조를 갖게 되었고 CPU보다 훨씬 많은 연산 코어, 더 높은 메모리 대역폭, 그리고 더 낮은 에너지 소비. 이 세 가지가 결합한 결과는 다음과 같이 정리할 수 있다.
ü NVIDIA H100 GPU 1장의 성능은 2008년 8코어 CPU 대비 약 630배
ü CPU 112코어와 비교해도 약 7배 빠른 수준
ü 단순한 성능 향상이 아닌, CFD 시뮬레이션 환경의 패러다임 전환 의미
n 가성비의 재계산 : GPU는 정말 비싼가 ?
GPU 도입을 검토하는 모든 엔지니어가 처음 만나는 벽은 ‘비싸다’는 인식이다. 이것은 앵커링 효과에 가깝다. 처음 눈에 들어온 단가라는 숫가가 머릿속에 닻처럼 박혀, 그 이후의 모든 판단을 왜곡한다. 이것을 증명하기 위해 CPU와 GPU의 동일 성능을 유지하기 위해 필요한 TCO를 분석해 봤다.
2026년 4월 기준으로 Intel Xeon Gold 6548N(32코어) 한 개가 약 650만원(Intel 공식, 환율 1,500원 적용), NVIDIA H100 NVL 한 장은 약 4,550만원(다나와)이다. 단순 비교 시 NVIDIA GPU가 7배가량 비싸다. 하지만 태성에스엔이 내부 벤치마크 결과, Combustor(24M cells) 케이스에서 H100 GPU 1장이 내는 연산 속도를 CPU로 따라잡으려면 약 20개의 Xeon CPU(624코어)가 필요하다. 이를 환산하면 다음과 같다.
|
항목 |
CPU |
GPU |
비교 |
|
가격 |
6,510,000원/개 |
45,500,000원/개 |
CPU의 경우, 노드(서버) 구성 시 주변장치 등이 추가되면서 실제 비용과 전력 부담은 더욱 가중됨. |
|
Cores |
624Cores |
1GPU |
|
|
CPUs |
20CPUs |
1GPU |
|
|
소비 전력 |
250W/CPU |
400W/GPU |
|
|
총 금액 |
130,200,000원 |
45,500,000원 |
CPU 대비 2.9배 저렴 |
|
총 소비 전력 |
5,000W |
400W |
CPU 대비 12.5배 감소 |
[표 1] CPU VS GPU, 같은 일을 해내는 데 드는 총비용(TCO)
단순하게 비교하더라도 초기 투자비는 약 2.9배, 소비 전력은 약 12.5배 차이가 난다. 게다가 이 비교는 CPU에 유리하게 설정된 조건이다. 실제로 624코어 CPU 클러스터를 구성하려면 기본 10개의 노드가 필요하기 때문에 그에 따른 네트워크, 스토리지 등의 하드웨어와 전력이 추가로 발생한다. 그렇기 때문에 단품 가격표만 보고 “GPU는 비싸다”고 결론짓는 것은, 빙산의 일각만 본 판단이다.
n Native GPU Solver 벤치마크 테스트: 우리 환경에서는 얼마나 빨라질까?
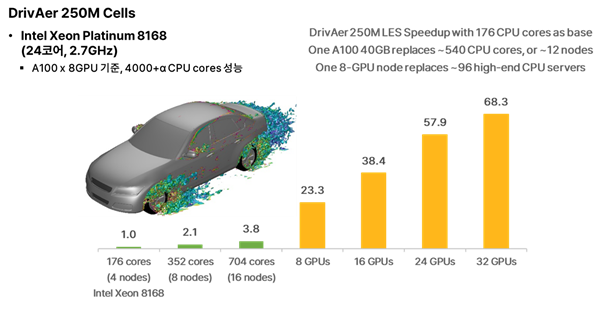
[그림 4] Ansys 공식 Benchmark Test 결과: CPU 176Cores 대비 속도 향상
Ansys 공식 자료의 화려한 숫자가 ‘우리 회사 장비에서도 재현될까?’ 라는 의문은 자연스럽다. 그래서 필자는 지난 1년간 사내 자원과 ‘경북대학교 첨단정보통신융합산업기술원(대구 AI 공정혁신 시뮬레이션 센터)’의 GPU를 두루 활용해 직접 벤치마크를 수행했다. 4가지 테스트 케이스(Mixing Tank 4M, Truck 6M, Combustor 24M, DrivAer 50M)를 11종의 GPU 구성과 비교했고, HPC Pack 보유 수준(1task & 3tasks)별로 결과를 정리했다.
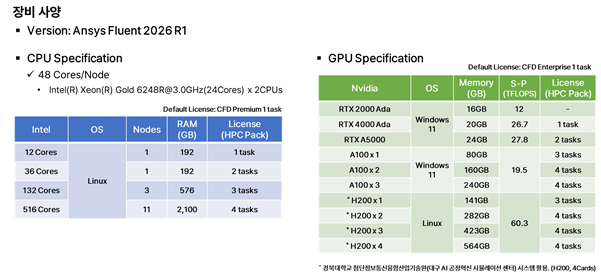
[그림 5] 태성에스엔이, Benchmark Test 환경
전체 결과는 eTSNE Portal의 전문자료실에서 ‘Ansys Fluent, Native GPU Benchmark 테스트(2026.04.15)’ 자료를 참고하기 바라며, 본 매거진에서는 핵심 인사이트(HPC Pack 1 & 3 tasks)만 압축해서 설명하겠다.
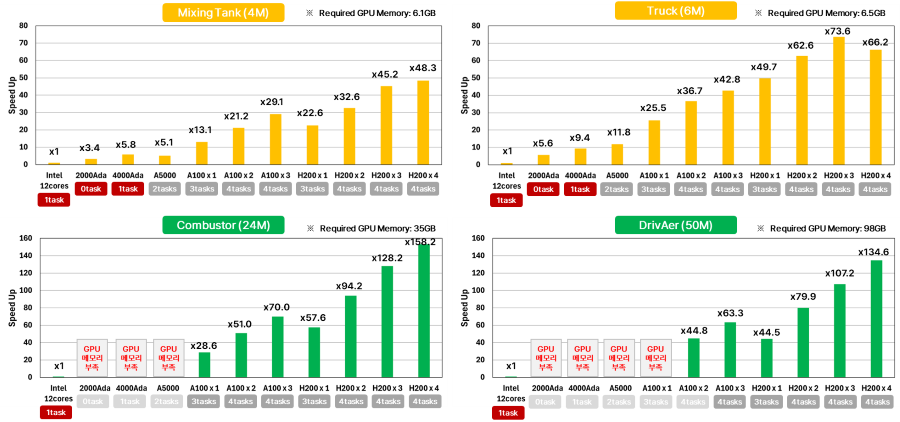
[그림 6] HPC Pack 1task 기준, CPU 12코어 대비 GPU 성능 향상 그래프
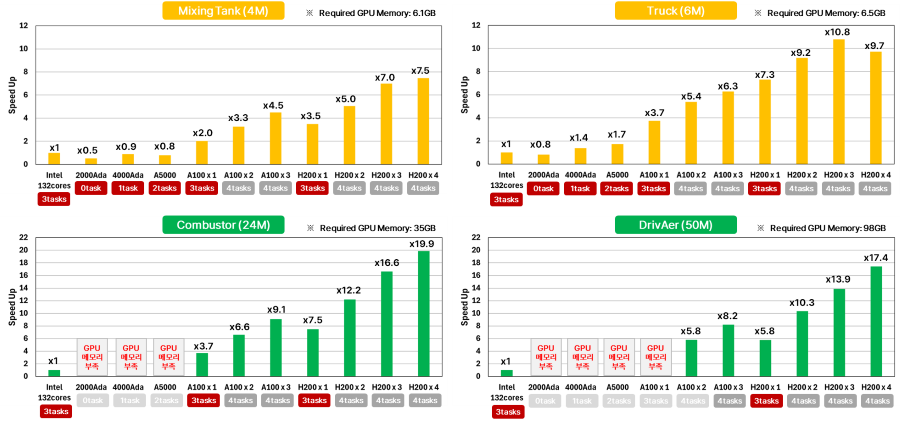
[그림 7] HPC Pack 3tasks 기준, CPU 132코어 대비 GPU 성능 향상 그래프
특히 주목할 점은 두 가지다.
첫째, RTX 2000 Ada처럼 저렴하고 HPC 라이선스가 불필요한 GPU 조차도 CPU 12코어 보다 3배 이상의 성능을 낸다는 점이다.
둘째, A100 또는 H200과 같은 서버 전용 GPU는 모델 규모가 커질수록 가속비가 오히려 커지는 경향이 뚜렷했다. 격자가 크고 모델이 무거울수록 GPU의 병렬성 이점이 더 잘 발현되는 것이다.
벤치마크 테스트 결과를 기반으로 생각해 보면, 수 시간이 걸리던 계산이 수 분으로 단축될 수 있다는 것과 서론에 언급한 것처럼 100번 이상의 Parametric study도 거짓이 아니라는 것을 알 수 있다.
|
HPC License |
벤치마크 케이스 종류 |
GPU 카드 |
GPU 속도 향상 |
|
HPC Pack 1 (CPU 12코어) |
Mixing Tank (4M) Truck (6M) |
RTX2000Ada ~ RTX A5000 |
3.4배 ~ 9.4배 |
|
HPC Pack 2 (CPU 36코어) |
1.3배 ~ 4.6배 |
||
|
HPC Pack 3 (CPU 132코어) |
Combustior (24) DrivAer (50M) |
A100 ~ H200 |
3.7배 ~ 7.5배 |
|
HPC Pack 4 (CPU 516코어) |
1.8배 ~ 9.5배 |
[표 2] 태성에스엔이, Benchmark Test 결과 요약
n Native GPU Solver 도입 로드맵
GPU Solver 도입은 단순히 ‘장비를 산다’는 결정이 아니라, 라이선스, 하드웨어 환경을 함께 점검하는 과정이 필요하다. 실무 관점에서 다음 순서를 권한다.
1. Ansys 라이선스 점검
Native GPU Solver는 CFD Enterprise 또는 CFD HPC Ultimate 레벨에서만 사용 가능하다. CFD Pro/Premium 레벨 사용자는 Enterprise로 업그레이드를 우선 검토해야 한다. 여기서 Enterprise는 기본 40SMs/CUs를 제공하며, GPU 카드 한 장당 필요한 SM/CU 수가 40을 넘으면 HPC 또는 HPC Pack 라이선스를 추가하거나 1 Job 당 무제한 사용이 가능한 HPC Ultimate를 구매해야 한다.
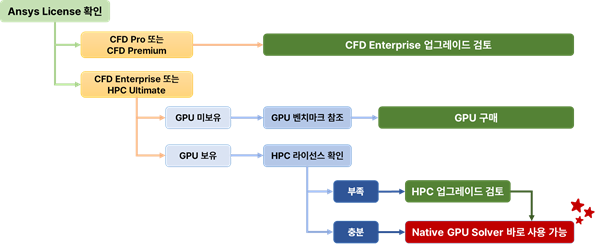
[그림 8] Ansys Fluent의 Native GPU Solver 도입을 위한 체크 리스트
2. 워크로드에 맞는 GPU 선정
무조건 최상의 GPU 카드를 사는 것이 답은 아니다. GPU 선택 시 우선 검토할 3가지 스펙은 이론 연산 속도(FP32, Single precision), 메모리 크기, SM/CU(HPC 라이선스 관련)이다.

[그림 9] GPU 종류별 기본 스펙 (www.techpowerup.com)
특히 GPU 메모리 크기는 ‘계산이 가능한가’를 결정짓는 중요한 요소이다. GPU 메모리가 부족하면 계산을 진행할 수 없기 때문이다. [그림 10]은 특정 케이스에 대한 예상되는 메모리 사용량을 나타낸 표이다. 메모리는 격자 타입, Physics model 등에 따라서 달라진다.
그렇기 때문에 가능하면 Ansys와 태성에스엔이에서 진행한 다양한 벤치마크 데이터를 활용해서 우리 회사에 적합한 GPU 카드를 선택하는 것을 추천한다. (또는 태성에스엔이 기술지원 담당자와 상의해 볼 것을 권장한다.)
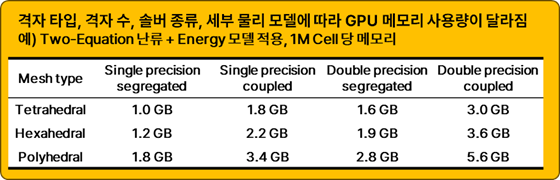
[그림 10] Native GPU Solver의 메모리 사용량 예시
3. 시스템 환경 점검
CPU와 시스템 메모리(이하 RAM)도 무시할 수 없다. Fluent 계산은 GPU가 수행하지만, I/O와 일부 전처리 및 후처리는 여전히 CPU와 RAM의 도움이 필요하기 때문이다. 코어가 많거나 고사양의 CPU를 필요로 하는 것은 아니다. 하지만 RAM은 최소한 ‘장착된 GPU VRAM의 합’ 이상으로 확보하는 것이 좋다. 만약 32GB의 GPU 카드 2장을 사용해서 GPU 계산을 실행하는 경우라면, RAM의 여유 용량은 64GB 이상을 확보하는 것을 권장한다.
또한 NVIDIA GPU는 CUDA 11.8(2025R1) 또는 CUDA 12.8(2025R2/2026R1) 이상, AMD GPU는 ROCm 6.0 이상의 드라이버 환경이 필요하며, AMD GPU는 현재 Linux 환경에서만 지원된다.
n 맺음말
CFD 엔지니어에게 Speed, Scale, Accuracy는 단순한 키워드가 아니라 매 프로젝트마다 마주하는 현실의 벽이다. 그 셋을 어떻게 다룰지가 곧 설계의 품질을 좌우한다. 이 글에서 GPU Solver를 거듭 강조한 이유도 거기에 있다.
지난 1년의 벤치마크와 경험을 통해 내린 결론은 명확하다. Ansys Fluent의 Native GPU Solver는 더 이상 "검토해 볼 만한 신기능"이 아니라, 세 가지 숙명적 과제를 동시에 풀어내는 실질적 수단이다. CFD가 요구하는 모델의 복잡도와 정밀도가 빠르게 올라가는 지금, GPU Solver는 이미 ‘선택’의 문제가 아니라 ‘필수’의 영역으로 넘어가고 있다.
Native GPU Solver가 우리에게 안겨주는 가치는 다음 네 가지로 요약된다.
첫째, 시간의 장벽을 무너뜨린다. 일주일이 걸리던 계산이 하룻밤 만에 끝난다. 마감에 쫓겨 포기해야 했던 정밀 해석을, 이제는 마감 안에 끝낼 수 있다.
둘째, 더 복잡한 현실을 다룰 수 있다. 수십억 격자의 대규모 모델, 충분한 격자 해상도, LES와 같은 고급 수치 모델 — 그동안 "하고 싶어도 못했던" 계산이 일상의 영역으로 들어온다. 이것은 곧 시뮬레이션 정확도의 도약을 의미한다.
셋째, 진정한 의미의 설계 최적화가 가능해진다. 수백 번의 Parametric 계산이 합리적인 시간 안에 가능해지면서, "최적에 가까운 설계"가 아니라 "실제로 최적인 설계"를 찾을 수 있다.
넷째, AI 학습용 시뮬레이션 데이터 확보가 현실이 된다. AI 기반 설계와 Surrogate model이 가속화되는 시대에, GPU Solver는 양질의 학습 데이터를 충분히 생산할 수 있는 거의 유일한 솔루션이다. 다가오는 AI × CAE 시대의 기반 인프라인 셈이다.
새벽 2시에 마감을 기다리던 그 풍경이 적어도 같은 모습으로 반복될 필요는 없다. 더 정밀한 모델을, 더 자주, 더 빠르게 같은 예산으로 더 많은 가능성을 검토할 수 있는 환경이 이미 우리 옆에 와 있다.
n 감사의 글
이번 벤치마크 테스트의 NVIDIA H100 및 H200 GPU 연산 환경은 경북대학교 첨단정보통신융합산업기술원(대구 AI 공정혁신 시뮬레이션 센터)의 시스템을 활용하여 구축되었습니다. 해당 시스템은 GPU 연산 환경이 사전에 최적화되어 있어, 추가적인 환경 설정 없이도 효율적인 테스트 수행이 가능하였습니다. Ansys Fluent의 GPU 연산 수행에 필요한 장비 사용을 지원해 주신 센터 관계자분들께 깊은 감사를 표합니다.
n 참고자료




 ㈜태성에스엔이
㈜태성에스엔이-
- 대표이사 : 심진욱, 박인규
- 사업자등록번호 : 219-81-23192
- 통신판매업 신고번호 : 제2017-서울성동-1100호
ⓒ TAE SUNG S&E Inc.